
For the past few years, the Common Criteria program has been mandating entropy analysis for almost all protection profile based evaluations. Since November 2020, NIST 800-90B has also become a mandatory requirement under the FIPS 140-2 and the forthcoming FIPS 140-3 program, meaning there is evaluation of entropy sources in both major North American security standards. Over the past few years, NIST has been fine-tuning an entropy analysis process to help quantify entropy sources as per the 800-90B standard. Their work can be found on the NIST public github page. In addition, new development on a web-based submission process has begun called the “Entropy Source Validation” program (ESV). This process will accept data from a registered entity and process the entropy source data via the NIST 800-90B entropy analysis tool.
This article focuses on an important, but sometimes overlooked, aspect of the entropy source validation process: ensuring the data is in a format appropriate to be read by the entropy assessment tool.
At the time of this article, if you were to run the NIST 800-90B entropy analysis tool for (say) the non-IID variant, there is a relatively innocuous statement in the usage screen which states the following:
Samples are assumed to be packed into 8-bit values, where the least significant ‘bits_per_symbol’ bits constitute the symbol.
This simple statement provides the reader with a glimpse of the appropriate input format, but also hints at the subtle ability for a user to dramatically affect their analysis if not careful. To give a full impression of the input semantics, consider the calling structure of the tool:
Usage is: ea_non_iid [-i|-c] [-a|-t] [-v] [-l <index>,<samples> ] <file_name> [bits_per_symbol]
The “bits_per_symbol” is an optional positional parameter provided at the end of the parameter set. It can range between 1 and 8, inclusive. If not provided, then the tool will attempt to “infer” the bit size by measuring the highest order of set bits found in each distinct byte of the input.
Normally, as a lab, we do not care about the format of the data that a vendor provides to us for analysis because we can always convert it to the appropriate format once we have more information about the sample’s domain and range. However, if you are a vendor and want to validate your own entropy as a NIST 800-90B sanity check, then you need to ensure you carefully construct the data properly.
The first thing to consider is that the maximum size of the entropy sample is 8-bits. If you have entropy samples which are longer than 8 bits, then you need to engage in selective bit-ranking as per NIST 800-90B section 6.4. This just means that you need to pick your best candidate bits that are expected to contain the most unpredictable qualities. You can pick up to 8 of them and you need to pick them according to a deterministic algorithm. Section 6.4 of 800-90B provides one such algorithm, though it is hardly definitive.
Once you pick your entropy sample bits, you are required to ensure they are in binary file format. (Unfortunately, for this article the term “binary” is overloaded because we will use it in two contexts. When we refer to a “binary file”, we are referring to a file such that the contents are not usually considered to be a “text file” since they can take on any of the 256 distinctive bit patterns found in an 8-bit grouping. When we refer to a “binary number”, we are referring to a singular 0 or 1 value.) You can imagine that if your selected entropy sample is 8-bits wide, then each contiguous byte in the binary file output will be successive entropy samples output in order of capture. However, if you have selected less than 8 bits in your sample, then you need to be very careful with your encoding.
In the latter case, each 8-bit byte is considered a loadable value. If you call the 800-90B tool with a specific “bits_per_symbol” value, however, the tool will only select those lower bits in each of the successive bits. The upper bits will be ignored and lost.
If you happen to use 4-bit samples and have encoded them as two samples per byte (with the upper nibble as the first sample and the lower nibble as the second sample), then the NIST 800-90B tool will incorrectly parse and analyze your data. If you fail to provide a “bits_per_symbol”, then each byte input will likely be inferred as an 8-bit wide sample instead of two 4-bit wide samples. If you do provide an explicit “bits_per_symbol” on the command-line, then the tool will skip every second sample since it is only going to mask the lower nibble and pad the remaining high bits with zeros.
To illustrate this, the NIST tool does the following when a 4-bit sample size is selected, irrespective of the original encoding of the input file:
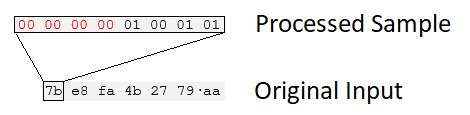
The red text is essentially a zero-pad applied once the lower four bits on the input are masked.
In order to correct this, you must write a transformation tool to alter your input data into a format which can be properly processed by the NIST tool. Specifically, you must be fully aware of the bit-width of your samples and how they are currently encoded so that you transform it properly. Any general-purpose programming language can do the trick, though Python is a very easy-to-use language and has capabilities within the “struct” package to pack and unpack data as necessary.
Entropy samples which are single-bit-oriented are subtly handled by the NIST 800-90B tool if you examine the output carefully. If your input data is bit-oriented or you are processing conditioned data (which must be treated as bit-oriented as per section 3.1.5.2 of NIST 800-90B), then running a binary file formatted data file will be (incorrectly) detected as a byte-oriented data file. However, the tool will, in parallel, run a bit-oriented analysis of the input as well. This is called “Hbitstring” in the output but is valid as a bit-oriented result. The alternative method (or the general purpose method) to ensure things are clearly being processed is to first read each byte in the input file, “explode” the byte into individual appropriately sized bits representing the samples, and then output those bits as a distinct binary digit in a binary formatted file. For example, if the input file is the following binary formatted file:
7b e8 fa 4b 27 79 aa 14 2a b4 0d 5d db 12 9b 39
0c 89 04 1e 1f b6 52 2e e7 6a f5 19 e2 ce ee 73
e0 e1 af 8f 91 56 95 df cd 97 7e 8b 6b 66 04 56
db ee f2 e0 27 4b 25 74 87 55 01 56 8f e6 e4 46
50 84 7c 0e 7f 68 30 f4 74 14 90 eb 33 e2 7d fb
… The first 4 bytes are 7b e8 fa 4b. In binary, this becomes 01111011 11101000 11111010 01001011.
Since the input file for the NIST 800-90B tool is byte-oriented, each of the bits in an entropy sample must be converted to an individual byte. If your samples are single-bit samples, then the converted binary hex dump immediately above will be: 00 01 01 01 01 00 01 01 01 01 01 00 01 00 00 00 01 01 01 01 01 00 01 00 00 01 00 00 01 00 01 01.... If your samples are two bits wide, then the individual binary bytes in the transformed file are: 01 03 02 03 03 02 02 00 03 03 02 02 01 00 02 03.... If your samples are 4 bits wide, then the individual binary bytes in the transformed file are: 07 0B 0E 08 0F 0A 04 0B....
Similar constructions operate for other multi-bit patterns between 3 and 7 bits.
Lightship recently contributed a pull request (PR) to the NIST 800-90B tool to incorporate aligned bit-packed input reading into the tool. Such a contribution will make it trivial to load entropy samples which are bit-packed and aligned on byte boundaries (the most common) and we hope that NIST will accept the premise behind the PR.
Lightship Security is an expert in entropy analysis for security certifications. Contact us to help you get through this complex task.
Greg McLearn is Lightship’s Technical Director. He has been doing Common Criteria and security certifications for 10+ years and enjoys getting his hands on some of the latest technology. He has authored several tools to help facilitate security testing.